Kindle Scribe to Mastodon
Posted on Mon 01 January 2024 in Digital Minimalism
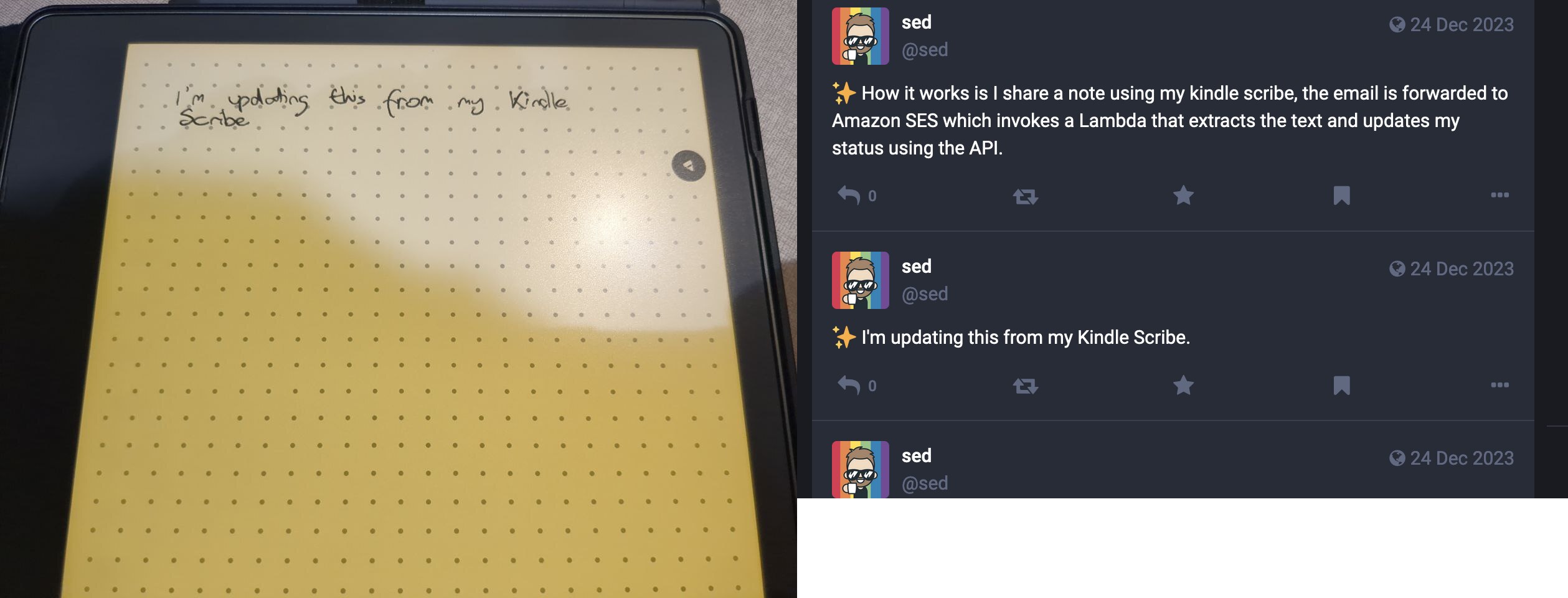
Kindle Scribe to Mastodon
Over the holidays, I put together a fun little project to put out status updates on Mastodon. Of course, I used some spare time to make this as overly-engineered as possible.
Stringing It All Together
I wanted this to be event-driven and serverless and to give me some experience toying with Terraform in AWS. Thankfully, what would be the most computationally challenging part is already handled by Amazon. The Kindle Scribe provides a means to convert a note to text and then email it to myself. I used my email provider to then forward it to AWS. I'm using Amazon to register a domain (click TLD domain names are only $3). I used route53 to hook that domain up to SES, then have SES invoke a Lambda when that particular email address is emailed from a particular email with a particular subject line. As I can't send the email body directly to a Lambda, I'll need to write it to a bucket first, then have the lambda read from the s3 bucket. (Thankfully SES does pass a MessageID to the Lambda so we know which MessageID refers to to which event), you could also trigger an event from a bucket change but SES already offered, so I figured this was a bit simpler. Now that I've got it all triggering a Lambda, I can throw code at this problem.
resource "aws_ses_domain_identity" "ses_domain" {
domain = "your_domain_name"
}
resource "aws_ses_domain_dkim" "ses_dkim" {
domain = aws_ses_domain_identity.ses_domain.id
}
output "ses_domain_verification_token" {
value = aws_ses_domain_identity.ses_domain.verification_token
}
output "dkim_tokens" {
value = aws_ses_domain_dkim.ses_dkim.dkim_tokens
}
resource "aws_ses_receipt_rule_set" "main" {
rule_set_name = "main-rule-set"
}
resource "aws_ses_receipt_rule" "store_in_s3_and_invoke_lambda" {
name = "store-in-s3-and-invoke-lambda"
rule_set_name = aws_ses_receipt_rule_set.main.rule_set_name
recipients = ["your_inbound_email@your_domain_name", "do-not-reply@amazon.com"]
enabled = true
scan_enabled = true
add_header_action {
position = 1
header_name = "Custom-Header"
header_value = "Added by SES"
}
s3_action {
position = 2
bucket_name = aws_s3_bucket.email_bucket.bucket
}
lambda_action {
position = 3
function_arn = "arn:aws:lambda:<region>:<account_id>:function:ProcessEmail"
invocation_type = "Event"
}
depends_on = [aws_lambda_permission.allow_ses]
}
# Grant SES permission to invoke the Lambda function
resource "aws_lambda_permission" "allow_ses" {
statement_id = "AllowExecutionFromSES"
action = "lambda:InvokeFunction"
principal = "ses.amazonaws.com"
function_name = "${aws_lambda_function.process_email.function_name}"
}
output "ses_domain_identity_arn" {
value = aws_ses_domain_identity.ses_domain.arn
}
resource "aws_ses_email_identity" "email_identity" {
email = "<your_recipient_email>"
}
resource "aws_s3_bucket" "email_bucket" {
bucket = "<your_email_storage_bucket>"
}
resource "aws_s3_bucket_policy" "allow_ses_write" {
bucket = aws_s3_bucket.email_bucket.id
policy = jsonencode({
Version = "2012-10-17",
Statement =[
{
Action = "s3:PutObject",
Effect = "Allow",
Resource = "${aws_s3_bucket.email_bucket.arn}/*",
Principal = {
Service = "ses.amazonaws.com"
}
}
]
})
}
resource "aws_iam_role" "lambda_exec_role"{
name = "lambda_exec_role"
assume_role_policy = jsonencode({
Version = "2012-10-17",
Statement = [
{
Action = "sts:AssumeRole",
Effect = "Allow",
Principal = {
Service = "lambda.amazonaws.com"
},
},
],
})
}
resource "aws_iam_policy" "lambda_policy"{
name = "lambda_policy"
policy = jsonencode({
Version = "2012-10-17",
Statement = [
{
Action = [
"s3:GetObject",
"s3:ListBucket",
],
Effect = "Allow",
Resource = [
"${aws_s3_bucket.email_bucket.arn}",
"${aws_s3_bucket.email_bucket.arn}/*",
],
},
{
Action = [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents",
],
Effect = "Allow",
Resource = "arn:aws:logs:*:*:*",
},
],
})
}
# Attach the policy to the role
resource "aws_iam_role_policy_attachment" "lambda_attach"{
role = aws_iam_role.lambda_exec_role.name
policy_arn = aws_iam_policy.lambda_policy.arn
}
resource "aws_lambda_function" "process_email"{
function_name = "ProcessEmail"
handler = "lambda_function.lambda_handler"
runtime = "python3.10"
role = aws_iam_role.lambda_exec_role.arn
filename = "${path.module}/build/lambda_function.zip"
source_code_hash = filebase64sha256("${path.module}/build/lambda_function.zip")
timeout = 60
}
Parsing the Email
It's slightly complicated as Amazon doesn't attach the content directly to the email; they provide a link to grab the text document. Thankfully, it doesn't require authentication, so with a regex, we can grab the URL and extract the text. The file itself is text split into pages. As my use-case is to flip to a new page, write a status, and post it to the web, I always just need to extract the latest page text.
import boto3
import email
import urllib
import re
# Initialize S3 client
s3 = boto3.client('s3')
# Extract the message ID from the SES event
message_id = event['Records'][0]['ses']['mail']['messageId']
# Define the S3 bucket name and object key
bucket_name = '<your_bucket_name>'
object_key = message_id
# Get the email object from the S3 bucket
email_object = s3.get_object(Bucket=bucket_name, Key=object_key)
email_content = email_object['Body'].read()
# Parse the email content
parsed_email = email.message_from_bytes(email_content)
# Assuming the email is multipart
if parsed_email.is_multipart():
for part in parsed_email.walk():
# Find the HTML part of the email
if part.get_content_type() == 'text/html':
html_content = part.get_payload(decode=True).decode('utf-8')
# Extract the URL using regex
url_pattern = r'https://www\.amazon\.com/gp/f\.html\?[^"]+'
url_match = re.search(url_pattern, html_content)
if url_match:
file_url = url_match.group(0)
# Download the file content using urllib
try:
with urllib.request.urlopen(file_url, timeout=20) as response:
if response.status == 200:
file_content = response.read().decode('utf-8')
pages = re.split(r'Page \d+', file_content)
last_page_content = pages[-1].strip() # Get the last page content and strip leading/trailing whitespace
print("Content to be published:\n", last_page_content)
# send_blog_post(last_pagecontent) # Uncomment and replace with your function
else:
print("Failed to download the file. Status code:", response.status)
except Exception as e:
print("Error downloading the file:", e)
else:
print("URL not found in the email content.")
break
else:
print("Email is not multipart, unable to parse.")
Posting the Status
Now that we've got the text, it's time to post it online. As I'm using omg.lol, I will post it to my status.lol site, which will also submit it to my social.lol Mastodon account. Obviously, we can plug in any service that provides API access.
import re
import json
import urllib
def send_post(content):
address_name = "<your_omg.lol_name>"
api_key = "<your_secret>" # Extract from secret manager or parameter store
data = {"status": content, "external_url": "https://example.com"}
encoded_data = json.dumps(data).encode("utf-8")
# Prepare the request
url = f"https://api.omg.lol/address/{address_name}/statuses/"
headers = {"Authorization": f"Bearer {api_key}", "Content-Type": "application/json"}
req = urllib.request.Request(url, data=encoded_data, headers=headers, method="POST")
# Send the request
try:
with urllib.request.urlopen(req) as response:
response_body = response.read().decode("utf-8")
print("Response from server:", response_body)
except urllib.error.URLError as e:
print("Error sending request:", e.reason)
Quick Tip
If you're not confident Amazon will parse all your text correctly, you can always preview the conversion to text before emailing it. Just hit 'Convert to Text and Email', rather than 'Quick Send' it.
And that was a fun project that's started to motivate me to write more on my Kindle. In fact, I initially wrote this entire blog post on my Kindle. Thanks for reading!